In My quest to perform some more real-world use case testing with some of the frontier SOTA models, I decided to give them a challenge that would show not only their ability to research and come to conclusions, but also their ability to perform predictive analytics.
Being that it is early September and the NFL Season has just begun, it felt like a natural decision to showcase the models capabilities by tasking them with predicting the outcomes for a couple of upcoming football games. Deciding to randomly choose two Week 1 match-ups, I settled upon the following games to use for my testing:
Miami Dolphins at Indianapolis Colts
Las Vegas Raiders at New England Patriots
With the teams chosen, the next step was to craft a suitable prompt that would guide the models in their head-to-head challenge. The prompt used is as follows, with the only modification across both tests being the team match up they were to predict the outcome of:

With the models all given the same prompt, it was time to let them get to work. While perhaps less of a pertinent consideration comparatively to the models game score estimate, the order in which they finished may be of some interest to mention. Grok 4 Heavy was the first to finish, followed by Claude 4.1 Opus, followed by Gemini 2.5 Pro and ChatGPT 5 Pro finishing at around the same time.
The Grok 4 Heavy result was by far the least detailed of the bunch, culminating with an estimate that the Dolphins would win with a final score of 24-20. While it did mention some historical trends as well as point spreads, no additional information was used to estimate the games result.

The Claude 4.1 Opus result was quite odd, being written in the style of an article that would have been released FOLLOWING the games conclusion. The estimate included information about how Claude came to the result, but it was provided in an editorial manner and not the statistical and logical outcome that would perhaps have been expected for a test such as this.
Claude estimated the result as a 16-10 victory in favor of the Colts. Interestingly, Claude did mention the passing of the Colts long-time owner, estimating that a ceremony held during half time would re-energize the team and contribute to their victory. Also mentioned, was the crowd noise measurements as the stadium as well as the historical outcomes of the last X number of meetings between the two teams.

The ChatGPT 5 Pro Result was very thorough, estimating the Colts victory at 24-23. Interestingly, GPT mentioned the location and time of the game, being at the Colts stadium which would favor the Colts. Nice to see, was the mention of the injury report as well as some kicking game considerations. Finally, historical trends were mentioned, such as the Colts having not won a season opener since 2013. The result also uses the betting market consensus to come to a final score.

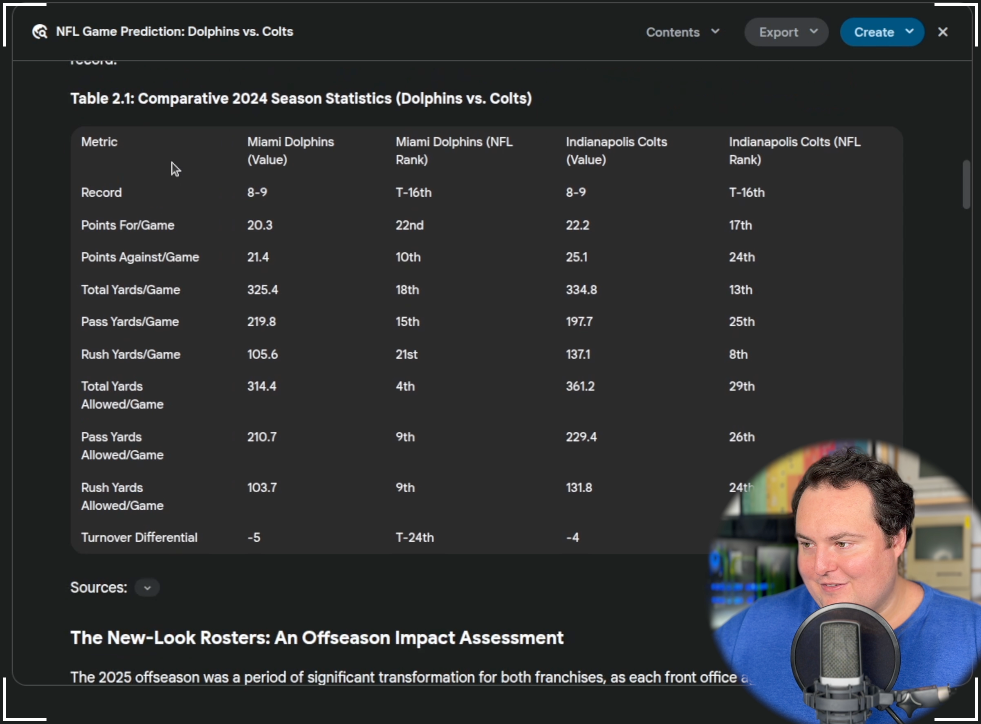
Finally, the Gemini 2.5 Pro result was perhaps the most verbose of the bunch. Including a very long list of sources (while all models did include, Gemini's were more prominently displayed in the result) as well as a table of the comparative 2024 season stats between the two teams. Gemini picked the Colts to win 23 - 20. Gemini also mentioned the home advantage as well as the emotional impact of wanting to honor their longtime owner. An injury report was also included and its impact on the potential outcome weighed.
Ultimately, three of the four models were in agreement that the Colts would win, with Grok being the only model to choose the Dolphins. The final scores of each model are listed below:
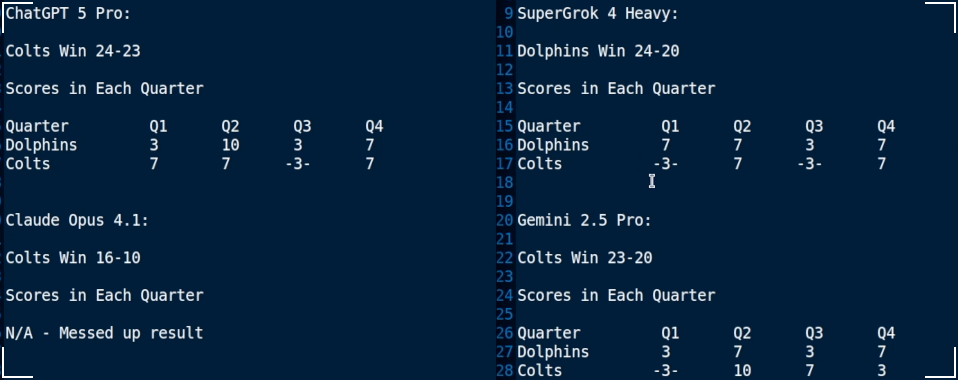
In addition to the final score, each of the models was asked to estimate the total number of points scored by each team in each quarter. The guesses are listed in the results table above, with any correct estimates denoted by a pair of dashes surrounding the result, such as the Grok 4 Estimation that the Colts would score 3 in the first quarter. Finally, the actual scoring breakdown of the game is as follows:
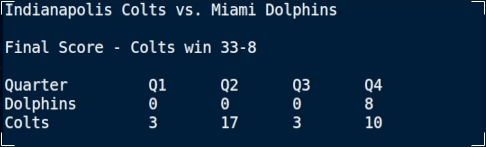
While none of the models accurately predicted the final score, three of them (Gemini, Claude, GPT) did accurately guess the winner to be the Indianapolis Colts. Grok was the only model to incorrectly estimate the winner, which may be due in part to its relatively lacking in depth analysis of why it had come to its conclusion.
As many games were set to begin at the same 1PM EST time zone, a second game was chosen to get more insight into the models capabilities. This was the Las Vegas Raiders at the New England Patriots. Interestingly, three of the models incorrectly estimated the Patriots would win (ChatGPT, Grok, Claude), while Gemini was the only model to correctly estimate the Raiders victory.
While the specific breakdown of each models assessment of this second game would be much of a repetition of the previous result, it would be prudent to mention that the Grok result, while once again incorrect was far more detailed with more sources cited. The Claude result was far more intricate and while still a bit cringe-inducing at the mention of things like "Historical Ghosts Haunt Raiders At Gillette Fortress", it did mention the rainy weather playing a factor as well as some key match ups between the two teams.
ChatGPT5 Pro also provided an in-depth result, mentioning the weather playing a significant factor in the games outcome, as well as some key match ups and other considerations. Finally, Gemini (the only to chose correctly) did not mention the weather forecast, but examination of its searched sources showed a lot of football related subreddit posts pertaining to the teams.
The final scores of this game, as well as each models estimates are provided below:
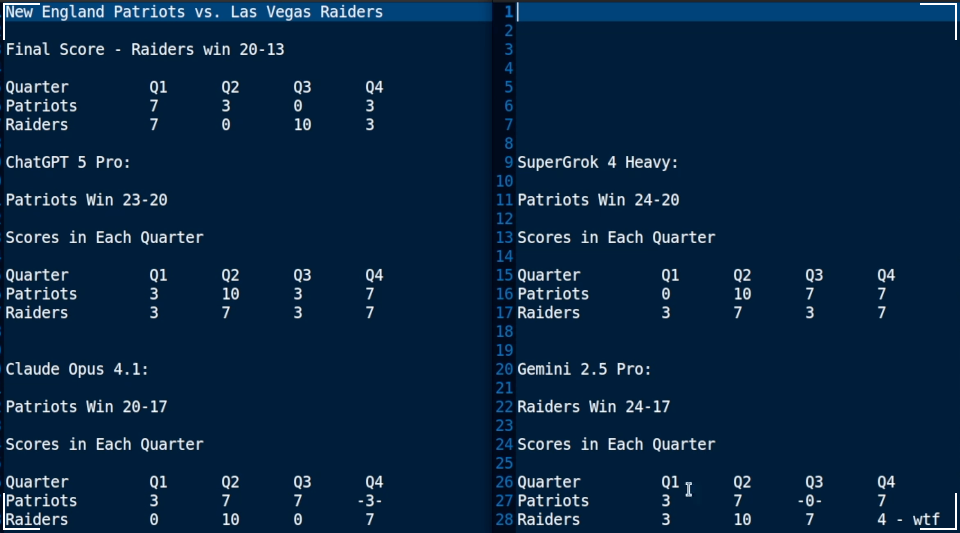
While Gemini was the only model to accurately predict the Raiders victory, I do find it most perplexing that it estimated the Raiders would score four points in the fourth quarter. A score of 4 is indicative of two safeties occurring, a relatively rare thing to happen in a single game, let alone twice in one quarter.

Overall, this test was an interesting way to asses these models capabilities in estimating outcomes based on real world and historical data. While no model accurately predicted the final score of a game, they did manage to properly guess the scores in certain quarters by certain teams, as well as an interesting delta between 75% of the models correctly estimating Game 1's winner, with only 25% of the models correctly estimating the winner of Game 2.
While impressive, it is important to note that I have not accidentally interchangeably used the terms "guess", "predict" and "estimate" throughout this writing. I do not advise placing any financial wagers based off any of the analysis of these models, especially when, as ChatGPT did mention, one single missed tackle, interception, etc, can completely change the trajectory of a game.
For more, check out my YouTube Channel: https://www.youtube.com/@bijanbowen
If you are interested in integrating AI into your business, you may book a consultation to speak with me at: https://www.bijanbowen.com